


Joel Pacheco Gonçalves
El debate sobre infraestructura de IA gira en torno a megavatios y GPUs. Pero la carga de trabajo de IA de más rápido crecimiento necesita algo más concreto: proximidad a las redes que sirven a personas reales.
La fiebre del oro tiene un punto ciego
Imagina que estás construyendo un data center para IA. Encuentras un terreno en Montana con energía abundante y barata, así que lo reservas. Sabes que la fibra no llega todavía, pero eso parece la parte fácil. Hasta que empiezas a planificar el tendido y te das cuenta de que hay que cruzar varios cursos de agua, gestionar permisos, y lo que parecía una conexión sencilla se convierte en una pesadilla de meses de retraso y sobrecostes.
Es un escenario que se repite de distintas formas en toda la industria. La infraestructura de IA se construye priorizando la energía. La conectividad viene después, si es que llega. Para ciertos tipos de carga de trabajo, eso funciona. Para el que más crece ahora mismo, es un problema.
El entrenamiento construye el cerebro. La inferencia lo pone a trabajar.
La mayoría de los titulares sobre infraestructura de IA hablan del entrenamiento: alimentar un modelo con enormes conjuntos de datos hasta que aprende a reconocer patrones, generar lenguaje o hacer predicciones. El entrenamiento es intensivo en cómputo y consume mucha energía. Un clúster de entrenamiento puede ubicarse en cualquier lugar con electricidad y refrigeración suficientes.
La inferencia es distinta. Es el modelo en producción. Responde tu pregunta, traduce tu videollamada, detecta una transacción fraudulenta. Funciona de forma continua, sirve a usuarios reales en tiempo real, y cada milisegundo de latencia importa.
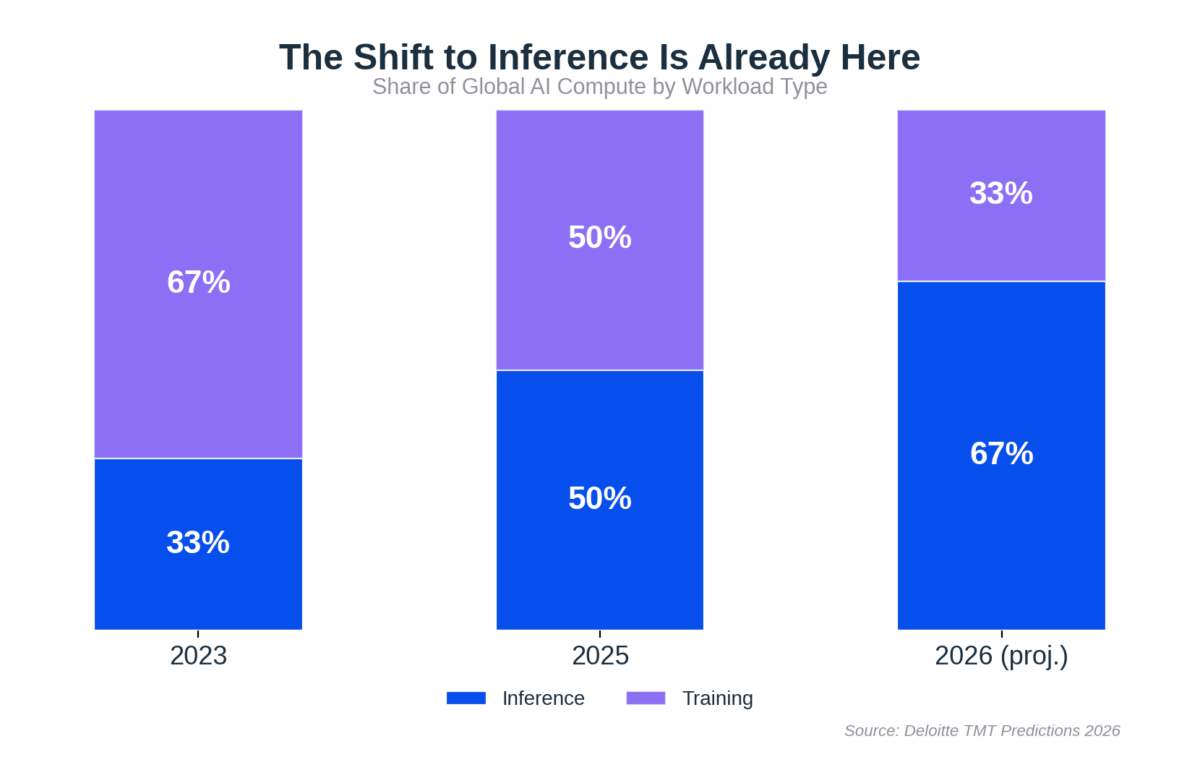
Este cambio ya está en marcha. Deloitte estima que la inferencia representó aproximadamente la mitad de todo el cómputo de IA en 2025, y prevé que alcance dos tercios antes de que termine este año. Como la inferencia no funciona en ráfagas sino de forma constante, puede representar entre el 80 y el 90% del coste total de un sistema de IA en producción.
El entrenamiento construye el cerebro. La inferencia es el cerebro trabajando. Y el cerebro trabajando necesita estar cerca de las personas a las que sirve.
Es un problema de red
El entrenamiento puede ocurrir en una nave industrial en medio de ninguna parte. La inferencia, no.
Las aplicaciones de IA en tiempo real necesitan redes que minimicen los tiempos de respuesta. El reconocimiento de voz, el procesamiento de vídeo y los sistemas autónomos: todos se degradan cuando la latencia aumenta. Por eso la inferencia se orienta hacia ubicaciones metropolitanas donde la infraestructura está próxima a los usuarios finales, con tiempos de respuesta típicamente inferiores a 10 milisegundos.
Sin embargo, hay un matiz que se pierde en el debate sobre la “IA en el edge”. Detrás de cada respuesta rápida en tu teléfono hay una cadena entera de infraestructura invisible: servidores metropolitanos, data centers privados, entornos multicloud y las redes que los conectan. El dispositivo se lleva el mérito. La red hace el trabajo.
Lo estamos escuchando de primera mano. En el Global Peering Forum de este mes, varios participantes señalaron que el perfil de conectividad de la inferencia se parece mucho más al peering tradicional y a la distribución de contenidos que a los grandes conductos que demandan los clústeres de entrenamiento. Para quienes trabajan en interconexión, las necesidades de infraestructura de la inferencia son, en realidad, terreno conocido.
Instalaciones de entrenamiento antiguas, nuevos desafíos
Una idea que gana adeptos es reconvertir instalaciones de entrenamiento más antiguas para inferencia. A medida que entran en servicio clústeres más nuevos y potentes, los edificios de generaciones anteriores podrían encontrar una segunda vida atendiendo cargas de trabajo de inferencia.
El problema es la ubicación. Esas instalaciones de entrenamiento se construyeron buscando energía barata y abundante, muchas veces lejos de cualquier punto de intercambio de Internet o ecosistema de red consolidado. Eso no era un impedimento para el entrenamiento, donde los datos se mueven en grandes lotes y unos milisegundos extra no tienen importancia. Para la inferencia, donde la proximidad a redes y usuarios lo es todo, sí es una limitación real.
El mercado parece confirmarlo. Grand View Research proyecta que el mercado global de edge AI alcanzará los 66.470 millones de dólares en 2030, con un crecimiento anual superior al 21%. Y un estudio de IDC del año pasado reveló que el 80% de los CIOs espera apoyarse en servicios edge para inferencia de IA en 2027. La gravitación hacia los lugares donde las redes ya convergen no es una teoría. Ya se refleja en las decisiones de inversión.
La inferencia necesita vecinos
Una reflexión surgida en NANOG 96 a principios de este año nos llamó la atención: la industria ha pasado del “data center como chip” a la “ciudad como chip”. Las restricciones de energía están distribuyendo los clústeres de GPUs entre múltiples instalaciones. Las conexiones entre esos edificios se vuelven tan importantes como lo que hay dentro de ellos.
Al mismo tiempo, los debates en GPF 2026 exploraron si los modelos de IA podrían eventualmente ejecutarse en cachés dentro de las redes de los ISPs, acercando la inferencia aún más al tramo final. Los puntos de intercambio de Internet, que ya evolucionaron cuando la nube transformó la industria, puede que tengan que volver a evolucionar.
El patrón es difícil de ignorar. La próxima ola de infraestructura de IA no se definirá únicamente por quién tiene más energía o el mayor clúster de GPUs. Estará determinada por quién ya cuenta con la densidad de red, el ecosistema y los vecinos de los que depende la inferencia.
Los operadores, ISPs, redes de contenidos y proveedores de nube que ya se interconectan en hubs consolidados son el cimiento de la era de la inferencia.





