


Joel Pacheco Gonçalves
The conversation around AI infrastructure is dominated by megawatts and GPUs. But the fastest-growing AI workload needs something more familiar: proximity to the networks that serve real people.
The Gold Rush Has a Blind Spot
Imagine you’re building a data center for AI. You find a site in Montana with plenty of cheap power, so you lock it in. You know the fiber isn’t there yet, but that feels like the easy part. Until you start planning the route and realize you’re crossing multiple bodies of water, navigating permits, and watching a simple connectivity buildout turn into a months-long, over-budget nightmare.
It’s a scenario playing out in different forms across the industry. AI infrastructure is being built power-first. Connectivity comes later, if it comes at all. For certain workloads, that’s fine. For the one that’s growing fastest right now, it’s a problem.
Training Builds the Brain. Inference Puts It to Work.
Most of the AI infrastructure headlines are about training: feeding a model enormous datasets until it learns to recognize patterns, generate language, or make predictions. Training is compute-heavy and power-hungry. A training cluster can sit anywhere with enough electricity and cooling.
Inference is different. It’s the model in production. Answering your question, translating your video call, and flagging a fraudulent transaction. It runs continuously, serves real users in real time, and every millisecond of delay matters.
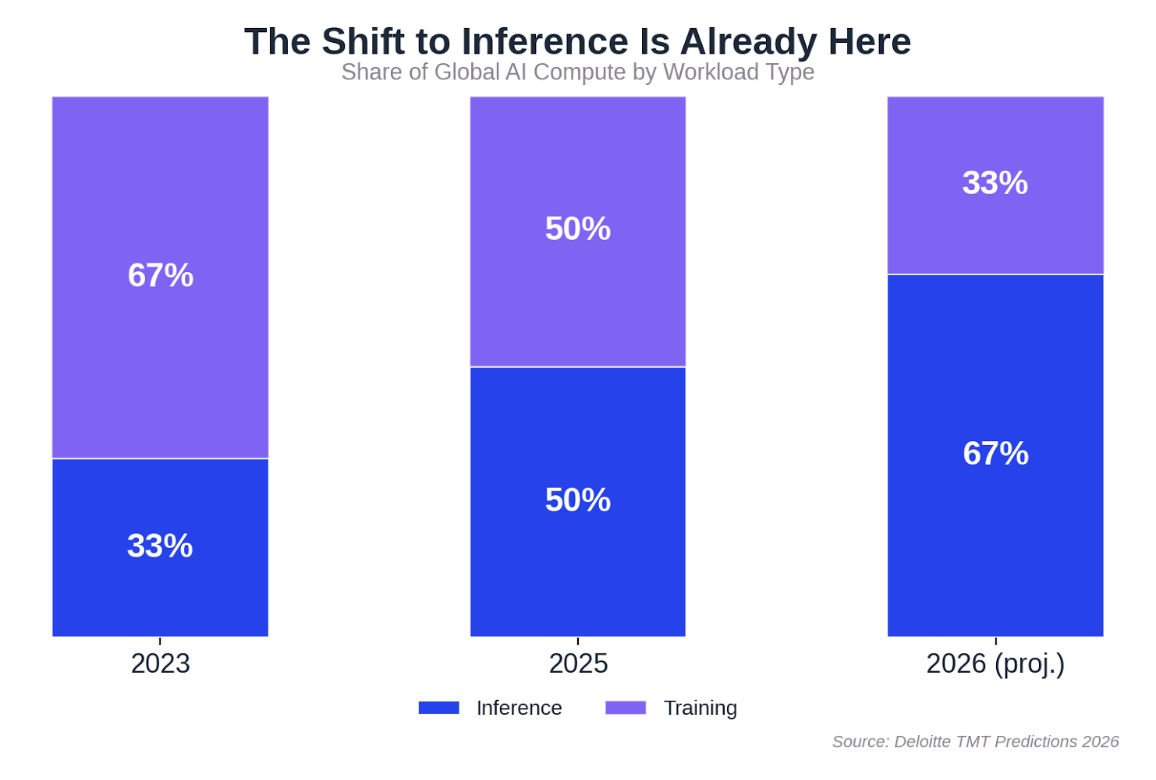
This shift is already well underway. Deloitte estimates that inference accounted for roughly half of all AI compute in 2025, and expects it to reach two-thirds by the end of this year. Because inference runs all the time, not in bursts, it can represent 80 to 90% of the lifetime cost of a production AI system.
Training builds the brain. Inference is the brain at work. And the brain at work needs to be close to the people it serves.
This Is a Network Problem
Training can happen in a warehouse in the middle of nowhere. Inference can’t.
Real-time AI applications need the network to minimize round-trip delays. Voice recognition, video processing, and autonomous systems: they all fall apart when latency creeps up. That’s why inference is gravitating toward metro locations where infrastructure sits close to end users, typically delivering responses in under 10 milliseconds.
There’s a subtlety that gets lost in the “edge AI” conversation, though. Behind every fast response on your phone, there’s a whole stack of invisible infrastructure: metro servers, private data centers, multicloud environments, and the networks tying them together. The device gets the credit. The network does the work.
We’ve been hearing this firsthand. At the Global Peering Forum earlier this month, several peers noted that the connectivity profile for inference looks a lot more like traditional peering and content delivery than like the massive pipes training clusters demand. For anyone in the interconnection world, the infrastructure needs of inference are actually familiar territory.
Old Training Sites, New Challenges
One idea gaining traction is repurposing older training facilities for inference. As newer, more powerful clusters come online, previous-generation buildings could theoretically find a second life serving inference workloads.
The catch is location. Those training sites were built for cheap, abundant power, often far from any internet exchange point or established network ecosystem. That was fine for training, where data moves in large batches and a few extra milliseconds don’t matter. For inference, where proximity to networks and users is the whole point, it’s a real limitation.
The market seems to agree. Grand View Research projects the global edge AI market will reach $66.47 billion by 2030, growing at over 21% annually. And an IDC study from last year found that 80% of CIOs expect to rely on edge services for AI inference by 2027. The pull toward places where networks already converge isn’t a theory. It’s already showing up in how people spend.
Inference Needs Neighbors
An insight that came up at NANOG 96 earlier this year stuck with us: the industry has gone from “Data Center as a Chip” to “City as a Chip.” Power constraints are pushing GPU clusters across multiple facilities. The connections between those buildings are becoming just as important as what’s inside them.
At the same time, conversations at GPF 2026 explored whether AI models might eventually run on caches inside ISP networks, pushing inference even closer to the last mile. Internet exchange points, which evolved once when cloud reshaped the industry, may need to evolve again.
The pattern is hard to ignore. The next wave of AI infrastructure won’t be defined only by who has the most power or the biggest GPU cluster. It will be shaped by who already has the network density, the ecosystem, and the neighbors that inference depends on.
The carriers, ISPs, content networks, and cloud providers that already interconnect in established hubs are the foundation of the inference era.





